
Eine Analyse der Define Media Group stellt den wirtschaftlichen Nutzen von KI-Chatbots für Publisher infrage. Trotz der rasanten Verbreitung von ChatGPT, Perplexity und anderen Large Language Models (LLMs) entfielen laut Similarweb im April 2026 lediglich 0,27 Prozent des gesamten Traffics der US-amerikanischen News- und Medienbranche auf generative KI.
Nach Angaben der Autoren nutzen inzwischen rund 100 Millionen Menschen in den USA regelmäßig KI-Chatbots. Dennoch würden die Systeme kaum Besucher an die ursprünglichen Quellen weiterleiten. Stattdessen verbleiben Nutzer innerhalb der jeweiligen KI-Plattformen, wodurch Verlage nur in geringem Umfang von der wachsenden Nutzung profitieren.
Inhalt
Verlage sollten Bots standardmäßig blockieren
Define Media Group empfiehlt Publishern eine Strategie nach dem Prinzip „Block by Default, Allow by Agreement“. KI-Crawler sollen demnach grundsätzlich gesperrt werden, sofern keine vertraglichen Vereinbarungen oder wirtschaftlichen Vorteile bestehen. Als Vorbilder nennt der Bericht unter anderem The Atlantic und People Inc., die bereits umfangreiche Bot-Blockaden umgesetzt haben.
Laut den Autoren reichen Einträge in der robots.txt-Datei nicht mehr aus. Viele KI-Crawler würden Sperranweisungen ignorieren oder technische Maßnahmen nutzen, um ihre Identität zu verschleiern. Genannt werden unter anderem Browser-Imitationen, wechselnde IP-Adressen und rotierende Netzwerke.
Sorge vor zunehmenden Zugriffen auf Paywall-Inhalte
Besonders kritisch bewertet die Studie spezialisierte Crawling-Dienste wie Exa, Firecrawl oder Tavily. Diese würden Inhalte teilweise auch dann erfassen, wenn bekannte KI-Bots bereits blockiert seien. In einem dokumentierten Fall konnte ein Dienst laut Define Media Group einen vollständigen, hinter einer Paywall liegenden Artikel innerhalb von 0,19 Sekunden abrufen.
Content Strategie für nachhaltige Sichtbarkeit im KI-Zeitalter
Von Themenstrategie und Keywordrecherche über fundierte Fachartikel bis zur laufenden Optimierung bestehender Inhalte: Wir setzen den gesamten SEO-Prozess strukturiert um und entwickeln KI-Systeme mit menschlicher Qualitätskontrolle.
Lassen Sie Ihre Website jetzt überprüfen und bereiten Sie sich aufs KI-Zeitalter vor!
Die Autoren warnen deshalb vor erheblichen Verlusten bei exklusiven Inhalten und empfehlen regelmäßige Audits, um bislang unbekannte Crawler zu identifizieren.
Google AI Overviews führen laut Analyse zu fast 50 Prozent weniger Klicks
Zusätzlich sieht die Define Media Group Risiken durch die zunehmende Integration generativer KI in die Google-Suche. Seit Einführung der AI Overviews seien die Klicks innerhalb des untersuchten Publisher-Netzwerks um 49 Prozent zurückgegangen. Gleichzeitig stammen laut Similarweb weiterhin rund 23 Prozent des Traffics der Nachrichtenbranche aus Suchmaschinen.
INSERT_STEADY_NEWSLETTER_SIGNUP_HERE
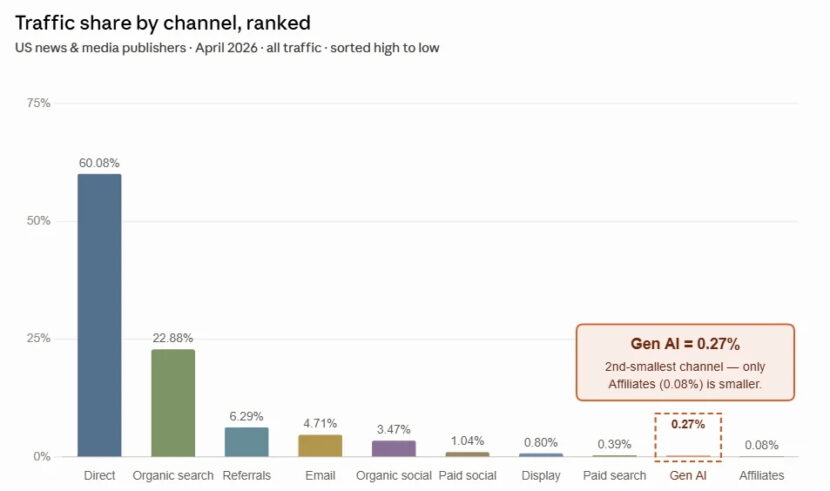
Sollte Google den Übergang von der klassischen Suchmaschine zu einer KI-basierten Antwortplattform weiter vorantreiben, könnten die Besucherzahlen von Publishern nach Einschätzung der Autoren noch stärker sinken. Langfristig müsse daher sogar die Frage diskutiert werden, ob Verlage Googlebot weiterhin uneingeschränkten Zugriff auf ihre Inhalte gewähren sollten.
Bot-Traffic überholt menschliche Nutzer
Laut Daten von Cloudflare hat automatisierter Bot-Traffic inzwischen den menschlichen Datenverkehr im Internet überholt. Mit der Verbreitung autonomer KI-Agenten dürfte dieser Anteil weiter steigen.
Define Media Group fordert daher eine stärkere Zusammenarbeit der Verlagsbranche. Publisher sollten technische Schutzmaßnahmen etablieren, den Zugriff von KI-Unternehmen kontrollieren und Lizenzmodelle entwickeln, um für die Nutzung ihrer Inhalte eine angemessene Vergütung zu erhalten.
KI-Bots sperren: Von robots.txt bis zur Netzwerkebene
Die klassische Methode zur Steuerung von Webcrawlern ist die robots.txt-Datei. Betreiber können dort festlegen, welche Bereiche einer Website von bestimmten Bots besucht werden dürfen und welche nicht. Viele KI-Unternehmen veröffentlichen inzwischen eigene User-Agents, die sich gezielt sperren lassen.
Beispiele sind:
Sie möchten eine kurze Einschätzung zur SEO-Performance Ihrer Website?
Schreiben Sie mich einfach an und nennen Sie mir die aktuellen Herausforderungen.
- GPTBot (OpenAI)
- ClaudeBot (Anthropic)
- Google-Extended (Google Gemini)
- PerplexityBot
- Bytespider (ByteDance)
- CCBot (Common Crawl)
Eine typische robots.txt-Regel sieht folgendermaßen aus:
User-agent: GPTBot
Disallow: /User-agent: ClaudeBot
Disallow: /
Das Problem: Die robots.txt ist rechtlich und technisch lediglich eine freiwillige Verhaltensregel. Bots können die Vorgaben einfach ignorieren. Deshalb setzen viele Publisher inzwischen auf mehrstufige Schutzsysteme.
Firewall- und CDN-Sperren
Anbieter wie Cloudflare, Akamai, Fastly oder DataDome analysieren Zugriffe auf Netzwerkebene. Verdächtige Bots werden bereits vor dem Abruf der Website blockiert.
Dabei kommen verschiedene Verfahren zum Einsatz:
- Erkennung bekannter Bot-IP-Adressen
- Analyse von Browser-Fingerprints
- Verhaltensanalysen
- Rate Limiting bei ungewöhnlich vielen Anfragen
- Captcha-Abfragen
- JavaScript-Challenges
Der Vorteil besteht darin, dass auch Bots erkannt werden können, die sich als normale Browser ausgeben.
Signierte Zugriffe und Bot-Verifizierung
Cloudflare unterstützt inzwischen Verfahren zur kryptographischen Bot-Verifizierung. Dabei müssen Bots nachweisen, dass sie tatsächlich vom angegebenen Unternehmen stammen. Das soll verhindern, dass unbekannte Crawler bekannte User-Agents wie Googlebot oder GPTBot imitieren.
Schutz von Paywall-Inhalten
Besonders wertvolle Inhalte werden zunehmend serverseitig geschützt.
Dazu gehören:
- serverseitige Paywalls statt JavaScript-Paywalls
- Zugriff nur nach Login
- Token-basierte Freigaben
- dynamische Auslieferung von Inhalten
- API-basierte Zugriffsmodelle
Diese Maßnahmen erschweren das automatisierte Auslesen kompletter Artikel erheblich.
Lizenzierung statt Komplettsperre
Einige Verlage verfolgen inzwischen einen anderen Ansatz. Statt alle KI-Crawler auszusperren, werden einzelne Anbieter gegen Lizenzgebühren zugelassen. So hat der Springer Verlag 2023 eine Zusammenarbeit mit ChatGPT vereinbart. Ob dies aber den massiven Rückgang des Traffics durch KI-Antworten ausgleichen kann, darf bezweifelt werden. Dennoch verfolgen einige große Verlage, Zugriffe technisch kontrollierbar zu machen und gleichzeitig neue Einnahmequellen über Kooperationen mit den großen KI-Anbietern zu schaffen.
Deutsche und europäische Rechtslage
Mit der DSM-Richtlinie (EU 2019/790) hat die Europäische Union vor dem Aufkommen der KI-Chatbots spezielle Regeln für Text- und Data-Mining eingeführt. Diese Regelung unterläuft nun den Schutz des Urheberrechts für Publisher. Artikel 4 erlaubt grundsätzlich das automatisierte Auslesen öffentlich zugänglicher Inhalte durch Unternehmen und KI-Anbieter.
Allerdings enthält die Richtlinie ein sogenanntes “Opt-out”-Recht. Rechteinhaber können maschinenlesbar erklären, dass ihre Inhalte nicht für Text- und Data-Mining verwendet werden dürfen. Während robots.txt technisch keine Sperre darstellt, kann sie in Europa als dokumentierter Widerspruch gegen die Nutzung von Inhalten für KI-Training interpretiert werden. Sobald die KI-Anbieter die robots.txt umgehen, haben Anbieter eine rechtliche Handhabe gegen das Scraping ihrer Inhalte.
EU AI Act erhöht den Druck auf KI-Anbieter
Zusätzliche Bedeutung erhält das Thema durch den EU AI Act.
Für General-Purpose-AI-Modelle gelten künftig Transparenzpflichten hinsichtlich:
- verwendeter Trainingsdaten
- Urheberrechts-Compliance
- Umgang mit Rechteinhaber-Vorbehalten
Anbieter müssen nachweisen können, wie sie urheberrechtliche Anforderungen berücksichtigen. Für Publisher könnte dies die Durchsetzung von Opt-out-Erklärungen künftig erleichtern.
Rechtslage bleibt in vielen Punkten ungeklärt
Trotz der neuen Regelungen laufen weltweit zahlreiche Verfahren gegen OpenAI, Google, Meta, Anthropic und andere KI-Anbieter. In Deutschland hat das Landgericht München gerade geurteilt, dass Google für seine KI-generierten Antworten in der Suche auch haften muss. Das ist ein wegweisendes Urteil, weil es die KI-Anbieter in Haftung nimmt. Bei der hohen Fehlerquote in KI-Antworten könnte das sehr teuer werden.
Weitere Fragen sind bislang völlig ungeklärt:
- Reicht eine robots.txt als wirksamer Nutzungsvorbehalt aus?
- Dürfen bereits erstellte Trainingsdatensätze weiter genutzt werden?
- Wann liegt eine urheberrechtlich relevante Vervielfältigung vor?
- Welche Vergütungsansprüche können Publisher geltend machen?
- Wie werden gesetzliche Vorgaben künftig kontrolliert?
Mit ersten Grundsatzurteilen wird in den kommenden Jahren gerechnet. Bis dahin setzen viele Verlage auf eine Kombination aus technischen Sperren, vertraglichen Lizenzmodellen und urheberrechtlichen Vorbehalten.
Sie möchten eine kurze Einschätzung zur SEO-Performance Ihrer Website?
Schreiben Sie mich einfach an und nennen Sie mir die aktuellen Herausforderungen.
Skalierbare Content-Produktion für Suche und KI
Wir konzipieren Content-Workflows zur teilautomatisierten Texterstellung für Unternehmen und Marken mit erklärungsbedürftigen Leistungen. Fachliche Kontrolle und Qualitätssicherung sind feste Bestandteile.
Jetzt Angebot anfordern
Udo Raaf (Geschäftsführer)

Udo Raaf ist Publisher und SEO-Berater mit über 15 Jahren Erfahrung in der strategischen Suchmaschinenoptimierung für Unternehmen, Agenturen und gemeinnützige Organisationen.
Sie möchten wissen, welches Potenzial in Ihrer Website steckt?
Füllen Sie den nachfolgenden Fragebogen aus für eine unverbindliche Ersteinschätzung Ihres Projekts. Ich arbeite mit einem erstklassigen Netzwerk aus Web-Entwicklern, KI-Experten und Autoren zusammen, um maßgeschneiderte Lösungen anzubieten.