Die Budgetplanung in Marketingabteilungen folgt seit jeher bewährten Mustern. Sobald ein neuer Kanal an Relevanz gewinnt, wird in Analyse-Tools investiert. Aktuell betrifft dies das sogenannte „KI-Tracking“ – das Messen der Sichtbarkeit von Marken und Produkten in den Antworten großer Sprachmodelle. Warum das nicht so funktioniert, wie viele sich das erhoffen, zeigt eine Studie von Rand Fishkin.
Schätzungen gehen von weltweit bereits über 100 Millionen US-Dollar aus, die jährlich für Analyse von KI-Antworten ausgegeben werden. Dabei wurde eine fundamentale Prämisse der Suchmaschinenoptimierung bisher blind auf die künstliche Intelligenz übertragen: die Annahme, dass es stabile, reproduzierbare Platzierungen gibt.
Eine groß angelegte Untersuchung von Rand Fishkin (SparkToro) und Patrick O’Donnell (Gumshoe.ai) vom Januar 2026 legt nun offen, dass die mathematische Realität von Sprachmodellen dieses Fundament komplett entzieht. Für Unternehmen bedeutet dies ein akutes Risiko, Budgets für unzuverlässige Metriken zu verschwenden und außerdem falsche Schlüsse aus diesen Daten abzuleiten.
Die Funktionsweise von Sprachmodellen als Antithese zum statischen Index
Um die Tragweite der Studienergebnisse zu verstehen, hilft ein Blick auf den technologischen Unterschied zwischen einer klassischen Suchmaschine und einem Large Language Model (LLM).
Eine Suchmaschine wie Google greift auf einen festen, gecrawlten Index zurück. Gibt ein Nutzer ein bestimmtes Keyword ein, filtert der Algorithmus die relevantesten Dokumente heraus und ordnet sie nach festen Kriterien. Das Ergebnis ist – abgesehen von Personalisierung und regionalen Unterschieden – weitgehend statisch.
Ein Sprachmodell hingegen generiert Text im Moment der Anfrage völlig neu. Es handelt sich um Wahrscheinlichkeitsrechner. Jedes ausgegebene Wort beeinflusst die statistische Wahrscheinlichkeit des darauffolgenden Wortes. Komplexe technische Zusammenhänge lassen sich hierbei gut mit einem Alltagsbeispiel verdeutlichen:
Eine klassische Suchmaschine agiert wie ein gut sortiertes Warenhaus. Wenn Sie nach einer bestimmten Pfanne fragen, führt Sie der Verkäufer immer an exakt dasselbe Regal in der Küchenabteilung. Ein Sprachmodell verhält sich eher wie ein flüchtiger Bekannter auf einer Party, den Sie nach einer Restaurantempfehlung fragen. Er nennt Ihnen spontan drei Lokale, die ihm gerade einfallen. Fragen Sie ihn eine Stunde später dasselbe, erinnert er sich vielleicht an zwei andere Restaurants oder nennt sie in einer völlig anderen Reihenfolge, weil sich seine innere Assoziationskette verschoben hat.
Genau dieses Phänomen der „stochastischen Papageien“ führt bei Produkt- und Markenempfehlungen zu einer extremen Volatilität, die ein verlässliches Tracking klassischer Natur unmöglich macht.
INSERT_STEADY_NEWSLETTER_SIGNUP_HERE
Die Studienergebnisse: Statistische Lotterie statt stabiler Platzierungen
Für die Untersuchung im Winter 2025/2026 ließen die Analysten 600 Freiwillige insgesamt 12 standardisierte Prompts durch die drei populärsten KI-Tools im US-Markt laufen: ChatGPT (OpenAI), Claude (Anthropic) und Googles KI-Übersichten (AI Overviews). Die Anfragen stammten aus unterschiedlichen B2C- und B2B-Sektoren. Insgesamt wurden 2.961 Antworten erfasst und normalisiert.
Das Ergebnis widerlegt die Annahme, man könne feste Plätze in KI-Antworten einnehmen oder messen.
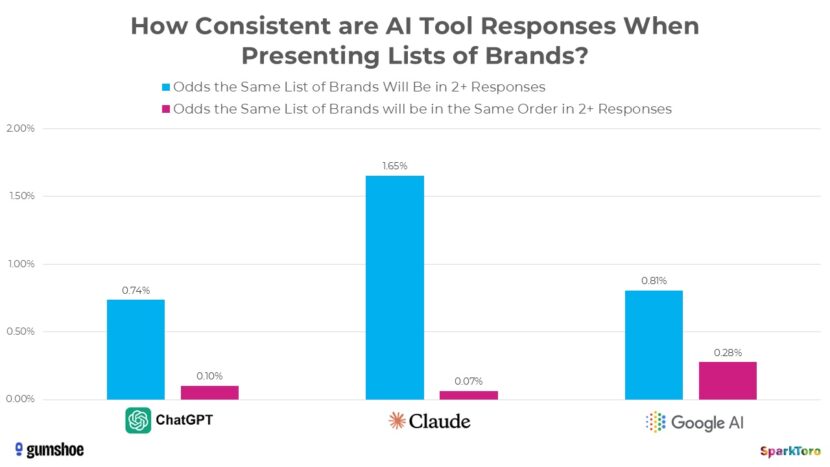
Die Varianz der Ergebnislisten
Wenn ein Nutzer ein Sprachmodell nach den besten Produkten einer Kategorie fragt, ist die Wahrscheinlichkeit, eine identische Antwort zu erhalten, verschwindend gering. Die Studie zeigt:
Sie möchten eine kurze Einschätzung zur SEO-Performance Ihrer Website?
Schreiben Sie mich einfach an und nennen Sie mir die aktuellen Herausforderungen.
- Die Chance, dass ChatGPT oder Googles KI bei 100 identischen Abfragen zweimal exakt dieselbe Liste an Marken ausgibt, liegt bei unter 1 Prozent.
- Claude zeigt sich minimal konsistenter bei der Auswahl der Entitäten, wirft die Reihenfolge jedoch noch drastischer durcheinander.
- Die Anzahl der empfohlenen Produkte pro Antwort variiert stark. Mal listet die KI nur zwei oder drei Optionen auf, ein anderes Mal zehn oder mehr – bei exakt gleichem Prompt.
Das Chaos der Reihenfolge (Rankings)
Noch deutlicher wird die Instabilität bei der exakten Platzierung innerhalb einer Liste. Die Wahrscheinlichkeit, dass zwei Listen bei wiederholter Abfrage dieselben Marken in derselben Reihenfolge aufführen, liegt bei unter 1 zu 1.000.
Ein konkretes Beispiel aus der Studie verdeutlicht dieses Verhalten: Bei der Abfrage nach dem besten Krebszentrum an der US-Westküste tauchte das „City of Hope“-Hospital in Los Angeles in 69 von 71 ChatGPT-Antworten auf. Das entspricht einer hohen Grundpräsenz. Allerdings belegte das Krankenhaus nur in 25 dieser Fälle den ersten Platz der Liste. In den restlichen Antworten rutschte es auf hintere Plätze ab oder wurde in anderen Kontexten genannt. Wer hier lediglich die Spitzenposition als Erfolg misst, erhält ein völlig verzerrtes Bild.
Diese Daten geben keinerlei Hinweise darauf, was man genau optimieren sollte, außer dem, was viele gerade stark vernachlässigen, wenn sie Zeit mit sinnlosen GEO-Tools verschwenden: SEO, PR und Produktqualität.
Der Einfluss der Marktdichte
Die Stärke der Fluktuation hängt maßgeblich davon ab, wie viele potenzielle Antworten das Modell in seinem Trainingskorpus vorfindet. Die Analysten stellten fest:
| Sektor / Thema | Anzahl der Optionen im Korpus | Paarweise Korrelation (Ähnlichkeit der Antworten) | Durchschnittliche Rang-Differenz |
| Cloud-Computing für SaaS-Startups | Sehr gering (wenige Marktführer) | Hoch | Niedrig (relativ stabil) |
| Science-Fiction-Romane (Neuerscheinungen) | Extrem hoch (Tausende Bücher) | Extrem niedrig | Hoch (völlig unvorhersehbar) |
Ein Anbieter von Cloud-Infrastruktur wird aufgrund der geringen Auswahl an Alternativen fast immer genannt werden. Ein Buchverlag hingegen verliert sich in der statistischen Masse. Jede Abfrage gleicht hier dem Ziehen einer Kugel aus einer riesigen Lostrommel.
Die Komplexität des menschlichen Suchverhaltens
Ein weiteres zentrales Ergebnis der Untersuchung betrifft die Formulierung der Anfragen. Im klassischen SEO sind Marketer daran gewöhnt, nach Suchvolumina von klar definierten Keyword-Kombinationen zu optimieren (z. B. „Kopfhörer Reise Test“). In der Interaktion mit KI-Assistenten verhalten sich Menschen jedoch komplett anders.
Die Studie analysierte 142 von realen Nutzern verfasste Prompts, die alle dieselbe Intention verfolgten: den Kauf eines Kopfhörers für ein reisendes Familienmitglied. Die Auswertung der semantischen Ähnlichkeit ergab einen Wert von gerade einmal 0,081. Das bedeutet, dass sich die Anfragen im Fließtext fast überhaupt nicht glichen. Nutzer schreiben hochgradig spezifisch, nutzen unterschiedliche Satzstrukturen, verschachtelte Kontextinformationen und individuelle Anekdoten.
Überraschenderweise zeigte sich hierbei jedoch eine Stärke der Sprachmodelle: Trotz der extrem unterschiedlichen Formulierung der Prompts filterten die KIs die Kernintention präzise heraus. Die Top-Marken wie Bose, Sony oder Sennheiser tauchten in 55 bis 77 Prozent der insgesamt 994 generierten Antworten auf. Die KI versteht den Kern, würfelt das Ergebnis im Detail aber dennoch jedes Mal neu aus.

Handlungsempfehlungen für Marketing-Verantwortliche
Um in dieser volatilen Umgebung keine Budgets an wirkungslose Analysen zu verlieren, sollten Unternehmen ein radikales Umdenken einleiten und Dienstleister mit folgenden Realitäten konfrontieren:
1. Stoppen Sie das Tracking von Einzelplatzierungen
Verlangen Sie von Ihren Agenturen und Software-Dienstleistern den sofortigen Verzicht auf Berichte, die feste Rankings in KI-Tools ausweisen. Solche Daten sind temporäre Momentaufnahmen eines stochastischen Prozesses ohne jede statistische Relevanz.
2. Akzeptieren Sie die „Black Box“: Es gibt keine validen Daten
Im Gegensatz zur klassischen Websuche (z. B. über die Google Search Console) stellen OpenAI, Anthropic, Google oder Microsoft keinerlei Primärdaten darüber bereit, welche Prompts echte Nutzer tatsächlich eingeben und welche Antworten sie erhalten. Jedes am Markt angebotene Tool simuliert lediglich synthetische Laborbedingungen über Entwickler-APIs. Ein echtes, datengetriebenes Abbild des realen Nutzerverhaltens ist technisch unmöglich und wird es vermutlich auch künftig nicht geben.
3. Die Personalisierungs-Barriere: Das Tracking von Phantomen
Moderne KI-Assistenten sind keine statischen Ausgabemedien. Die Ergebnisse variieren fundamental von Nutzer zu Nutzer durch:
- Das Langzeitgedächtnis: Die KI passt Empfehlungen an das individuelle Profil und frühere Chats des Nutzers an.
- Den Session-Kontext: Der Verlauf eines aktuellen Dialogs verzerrt die Relevanz im Moment der Abfrage.
- Geschlossene Ökosysteme: Interne Custom GPTs, Claude-„Projects“ oder firmeninterne, per RAG (Retrieval-Augmented Generation) mit eigenen Daten gefütterte KI-Instanzen sperren externe Tracking-Bots komplett aus.
Anbieter, die behaupten, diese hyper-personalisierte Realität über standardisierte API-Abfragen messbar zu machen, verkaufen statistische Phantome. KI-Sichtbarkeit zu messen ist derzeit vor allem ein Sales-Thema, der Nutzen für Kunden ist extrem gering und teilweise auch gefährlich, wenn sie sich nicht mehr ausreichend um die SEO-Basics kümmern oder gar Budgets aus SEO abziehen.
4. Aggregierte Metriken mit maximaler Skepsis nutzen
Falls Budgets für AI-Tracking-Plattformen freigegeben werden, dürfen diese ausschließlich für großflächige Massenabfragen (mindestens 60 bis 100 automatisierte Durchläufe pro Prompt-Cluster) genutzt werden. Diese messen jedoch nicht die Realität der Nutzer, sondern lediglich die unpersonalisierte, statistische „Grundgesamtheit“ (Baseline) des Modells. Ist eine Marke hier unsichtbar (0 % Sichtbarkeit), wird sie auch beim Nutzer nicht auftauchen. Zu mehr als einer groben Tendenz taugen diese Tools jedoch nicht. Ob sich die Kosten für fragwürdige Messungen trotzdem lohnen muss jeder für sich entscheiden.
5. Fokus auf das einzig Messbare: Markenpräsenz im offenen Web
Da das Tracking am Ende der Kette (in der KI) korrumpiert und unvollständig ist, muss das Budget an den Anfang der Kette verlagert werden: in die Optimierung der Datenbasis. Sprachmodelle spiegeln das wider, was sie im Trainingskorpus vorfinden. Die einzig verlässliche Strategie ist der kontinuierliche Aufbau einer starken, konsistenten und häufig erwähnten Präsenz auf autoritativen Fachportalen, in themenrelevanten Foren, Testberichten und im klassischen Web-Index. Nur wer das echte Netz dominiert, erhöht die mathematische Wahrscheinlichkeit, in personalisierten KIs aufzutauchen. SEO ist und bleibt die Basis für Sichtbarkeit und Relevanz.
Quellen
- Fishkin, Rand (2026): NEW Research: AIs are highly inconsistent when recommending brands or products; marketers should take care when tracking AI visibility. Veröffentlicht am 27. Januar 2026.
- Carnegie Mellon University (2025): Estimating LLM Consistency: A User Baseline vs Surrogate Metrics. (Als Modell für die paarweise Korrelationsanalyse der Studie genutzt).
Udo Raaf (Geschäftsführer)

Udo Raaf ist Publisher und SEO-Berater mit über 15 Jahren Erfahrung in der strategischen Suchmaschinenoptimierung für Unternehmen, Agenturen und gemeinnützige Organisationen.
Sie möchten wissen, welches Potenzial in Ihrer Website steckt?
Füllen Sie den nachfolgenden Fragebogen aus für eine unverbindliche Ersteinschätzung Ihres Projekts. Ich arbeite mit einem erstklassigen Netzwerk aus Web-Entwicklern, KI-Experten und Autoren zusammen, um maßgeschneiderte Lösungen anzubieten.
Content für Suche und KI
Wir konzipieren und produzieren hochwertigen Content für B2B-Unternehmen, der auch gefunden wird.
Fachliche Kontrolle, Keywordrecherche und Qualitätssicherung inklusive.
Jetzt Angebot anfordern