
Seit Google seine KI prominent in der Suche verankert hat und KI-Plattformen wie ChatGPT oder Perplexity als neue Anlaufstellen für Informationen fungieren, drängen wöchentlich neue GEO Tools (Generative Engine Optimization) auf den Markt. Doch sie alle haben ein großes Problem.
Wer die technische Architektur hinter Large Language Models (LLMs) versteht, erkennt schnell, dass die klassische SEO-Logik, die wir seit Jahrzehnten auf Google anwenden, hier nicht nur an ihre Grenzen stößt, sondern technisch ins Leere läuft.
Wir befinden uns aktuell in einer Phase, in der Tools Kontrolle suggerieren, wo in Wahrheit der Zufall regiert. Viele Bereiche der schönen neuen KI-Welt sind eine Blackbox, die wir weder messen, noch kontrollieren können. Das liegt in ihrer Funktionsweise begründet.
Kurz & Kompakt: Warum GEO-Tools oft scheitern
Viele neue GEO-Tools (Generative Engine Optimization) versprechen vermeintlich einfache Platzierungen in KI-Antworten. Doch technisch ist das kaum möglich:
- KI ist kein Index: Während Google eine feste Liste (Index) sortiert, berechnet eine KI Antworten jedes Mal neu basierend auf Wahrscheinlichkeiten. Eine Nennung in KI ist daher kaum mehr als eine flüchtige Momentaufnahme.
- Identitätsverlust: Informationen werden in KI-Modellen mathematisch vermischt. Oft „weiß“ die KI zwar etwas, kann die Quelle aber nicht mehr eindeutig zuordnen.
- Falsche Metriken: Suchvolumen und Rankings verlieren an Bedeutung. Wichtiger wird künftig die Zitierwürdigkeit von Inhalten.
- Die Folge: GEO Tools können zwar Tendenzen aufzeigen, aber keinen Einfluss nehmen. Wer in KI-Antworten stattfinden will, braucht echte Markenautorität und einzigartige Daten, um sich von der Masse abzuheben und zur „besten“ Lösung zu werden.
Das Fundament-Problem: Index vs. Wahrscheinlichkeit
Um zu verstehen, warum klassische Monitoring-Ansätze scheitern, müssen wir den fundamentalen Unterschied in der Datenausgabe betrachten. Die Google-Suche arbeitet deterministisch, LLMs hingegen arbeiten probabilistisch.
- Deterministische SERPs: Google nutzt einen festen Index, eine Art gigantische, sortierte Bibliothek. Wenn zwei Nutzer mit ähnlichem Profil nach „Beste Cloud-Software“ suchen, liefert der Algorithmus eine relativ stabile Liste (SERP) mit den passenden Ergebnissen. Diese Liste lässt sich crawlen, messen und in eine Datenbank schreiben. Ein „Platz 1“ ist hier ein realer Zustand im HTML-Code.
- Probabilistische Outputs: Ein LLM besitzt keinen Index, den es „sortiert“. Das Modell erzeugt fortlaufend Antworten Wort für Wort. Für jede Stelle berechnet es, welches Wort statistisch am wahrscheinlichsten als Nächstes passt.
- Der Stochastik-Faktor: Je nach interner Einstellung kann das Modell selbst bei identischer Frage leicht unterschiedliche Antworten erzeugen. Wer ein KI-Tool viermal fragt: „Was ist GEO?“ wird vier verschiedene Antworten mit unterschiedlichen Quellen bekommen. Beim „Googlen“ wird jedem Nutzer dieselbe SERP angezeigt.
In einem Sprachmodell existiert also kein fester Listenplatz wie bei Google. Eine Information ist entweder in den antrainierten Gewichten des Modells gespeichert oder wird via RAG (Retrieval-Augmented Generation) temporär in den Arbeitskontext geladen.
Da die KI die Antwort jedes Mal neu konstruiert, ist eine Messung der „Sichtbarkeit“ nicht möglich. Ein Tool, das heute „Platz 1“ meldet, sieht morgen vielleicht gar keine Nennung mehr, nicht, weil der Content schlechter wurde, sondern weil das Modell die Wahrscheinlichkeitsmatrix des Satzes minimal anders berechnet hat.
Die Blackbox der Informationsverdichtung
Einer der größten Trugschlüsse im GEO-Marketing ist die Annahme, dass eine Erwähnung in der KI-Antwort immer das Ergebnis einer aktuellen Optimierung auf der eigenen Website ist. In der Realität stehen wir vor einem unlösbaren Rätsel, wie die Antworten zusammengesetzt werden.
Warum KI keine Dokumente „findet“, sondern Antworten baut
Klassische Suchmaschinen sind Retrieval-Systeme: Sie finden ein Dokument und verweisen darauf. Ein LLM hingegen ist ein generatives System: Es verschmilzt Informationen aus unzähligen Quellen zu einer neuen, synthetischen Antwort. Wenn eine KI beispielsweise fünf verschiedene Testberichte liest, um einen Gasgrill zu empfehlen, generiert sie einen Textabsatz, der Fakten aus allen Quellen kombiniert und immer anders gewichtet. Oft geht dabei die eindeutige Kausalität verloren.
Mathematische Muster und Identitätsverlust
Sprachmodelle speichern Informationen nicht als Dokumente mit klarer Quellenangabe, sondern als mathematische Muster zwischen Begriffen (sogenannte Embeddings). Dabei geht die ursprüngliche URL-Zuordnung häufig verloren. Das Modell weiß zwar etwas, kann aber meist nicht mehr zuverlässig sagen, woher dieses Wissen eigentlich stammt.
Wenn ein GEO-Tool misst, dass eine Marke genannt wird, lässt sich also oft gar nicht zweifelsfrei belegen, ob dies auf den Inhalte zurückzuführen ist, auf Fragmente aus den ursprünglichen Trainingsdaten, die bereits Jahre alt sein können oder auf einen indischen Blogpost, schließlich können LLMs auch problemlos den Sprachraum wechseln, wenn sie das für angebracht halten.
Sie möchten eine kurze Einschätzung zur SEO-Performance Ihrer Website?
Schreiben Sie mich einfach an und nennen Sie mir die aktuellen Herausforderungen.
Warum Content-Optimierung allein oft ins Leere läuft
Viele GEO-Tools suggerieren nun, dass man durch das Hinzufügen bestimmter Keywords oder Strukturen sichtbar werden könne. Doch wenn die interne Gewichtung des Modells eine Marke aufgrund ihrer historischen Dominanz bereits fest verankert hat, kann man die Antwort durch reines Content-Tuning an der Oberfläche kaum noch beeinflussen. Die KI-Entscheidung, welche Quelle sie bevorzugt, entzieht sich unserem Einfluss.
Warum SEO-Metriken bei GEO versagen
In der SEO-Welt haben wir uns an ein festes Koordinatensystem gewöhnt: Wir messen Suchvolumina, beobachten Rankings auf einer Skala von 1 bis 100 und bewerten den Wettbewerb anhand von Backlinks. Dann optimieren wir Technik und Inhalte und überprüfen die Veränderung in den Rankings und wiederholen das ganze, bis wir endlich die Top Position erreicht haben. SEO-Erfolg ist steuerbar. Bei generativer KI bricht dieses Koordinatensystem jedoch zusammen, weil die Parameter, die eine KI steuern, fundamental andere sind.
Von festen Rankings zu Wahrscheinlichkeiten
Wir müssen uns von der Vorstellung verabschieden, dass es in einem LLM eine „Position“ gibt, die man besetzen kann. Da es keinen statischen Index gibt, den die KI sortiert, ist jede Messung einer Position nur eine Momentaufnahme einer statistischen Wahrscheinlichkeit. Ein Tool, das eine „Position 1“ ausweist, misst in Wahrheit nur ein Symptom, keine Ursache. Es gibt keinen permanenten Platz, den man „besitzen“ kann. Wer für KI-Systeme optimiert rät.
Vom Keyword zum zur Suchintention
Das klassische Suchvolumen basiert auf historischen Daten: Wie oft wurde exakt die Phrase „Beste Cloud-Software“ in das Suchfeld getippt? Bei KI-Plattformen zersplittert dieses Volumen in Millionen individueller Prompts. Nutzer formulieren ganze Absätze, geben persönlichen Kontext oder stellen hochspezifische Bedingungsketten auf. Ein SEO-Tool, das für ein Keyword ein Volumen von „0“ anzeigt, ist bei GEO blind: Das Thema kann in KI-Dialogen massiv präsent sein, wird aber durch die individuelle Sprache der Nutzer für klassische Keyword-Datenbanken unsichtbar. Statt einzelner Keywords müssen wir Themen und Suchintentionen ganzheitlich betrachten. Das macht die Contentarbeit wesentlich aufwendiger, als nur Keywordlisten abzuarbeiten.
Von der Domain zur Zitat-Autorität
Klassischer Wettbewerb wird oft über die Domain-Stärke und die Anzahl der Backlinks definiert. Doch LLMs „denken“ nicht in Link-Power. Sie suchen nach der präzisesten Antwortstruktur für den aktuellen Kontext. Einige Studien zeigen, dass in KI-Antworten oft Nischenseiten zitiert werden, die in der organischen Suche kaum eine Rolle spielen, aber eine extrem hohe „Citation-Readiness“ (Zitierfähigkeit) aufweisen. Ein Wettbewerbs-Score, der nur auf Backlinks basiert, führt im GEO-Bereich zu völlig falschen strategischen Schlüssen.
Google AI Overviews: Warum die Zahlen oft täuschen
Die AI Overviews in der Google-Suche wirken wie die perfekte Brücke: Sie sind Teil der vertrauten Google-Infrastruktur und tauchen sogar in der Google Search Console (GSC) auf. Doch genau hier lauert die Gefahr von Fehlinterpretationen. Die Messbarkeit der AIOs ist technisch zwar greifbarer als bei einem geschlossenen ChatGPT-Dialog, aber die Daten sind oft irreführend.
Auswirkungen auf die Google Search Console
Google hat die GSC zwar angepasst, um AIO-Impressionen zu erfassen, doch die Impression-Logik unterscheidet sich fundamental vom Standard-Reporting. Eine Impression wird oft schon gezählt, wenn der AIO-Block generiert wird, völlig ungeachtet dessen, ob der Nutzer den Block überhaupt aktiv ausklappt oder liest.
Das Ergebnis: Die Sichtbarkeit (Impressions) schießt scheinbar in die Höhe, während die Klickraten (CTR) massiv einbrechen. Wer diese Daten ohne den Kontext der generativen Suche liest, zieht zwangsläufig falsche Schlüsse über den Erfolg seiner Inhalte.
Unklare Herkunft von Klicks
Wenn ein Nutzer innerhalb eines AI Overviews auf einen Link klickt, ist dieser Klick zudem qualitativ anders zu bewerten als ein organischer Klick. In den Reports wird jedoch oft nicht differenziert: Stammt der Klick aus der KI-Zusammenfassung oder aus den klassischen Ergebnissen darunter? Da die AIOs oft den gesamten Bereich „Above-the-fold“ (den ohne Scrollen sichtbaren Bereich) einnehmen, verdrängen sie die organischen Ergebnisse so weit nach unten, dass herkömmliche Klickkurven ihre Gültigkeit verlieren.
Technische Hürden für Crawler und Tracking-Tools
Für externe Monitoring-Tools sind AIOs ein Albtraum. Google spielt diese Boxen oft individuell aus, das heißt, ein Nutzer sieht sie, der andere nicht. Laut Google wird diese Personalisierung der Suche künftig weiter zunehmen. Ein Crawler, der die SERPs scannt, erfasst also nur eine Momentaufnahme einer instabilen Umgebung.
Am Ende bleibt die Erkenntnis: Selbst wenn wir Daten sehen, messen wir eine flüchtige Oberfläche, einen zufälligen Ausschnitt. Die wirklichen Gründe, warum Google eine bestimmte Quelle für den AI Overview auswählt, bleiben auch hier tief im Modell verborgen und können sich jederzeit ändern.
Marktanalyse: Zwei GEO-Tools im Vergleich
Es gibt immer mehr Tools am Markt, die KI-Sichtbarkeit messen wollen, doch alle stehen vor denselben Problemen. Dabei haben sich zwei grundverschiedene Philosophien herausentwickelt, die an völlig unterschiedlichen Punkten der Kausalkette ansetzen.
1. Der Input-Ansatz (z. B. Sistrix Prompt Research)
Sistrix akzeptiert für sein neues Prompt Research Tool die Unmessbarkeit der KI-Antwort (Output) und wechselt stattdessen auf die Nachfrageseite (Input). Da Nutzer in KI-Plattformen keine statischen Keywords nutzen, sondern in natürlichen Sätzen kommunizieren, bricht das Tool Millionen von individuellen, flüchtigen Prompts auf eine strategisch analysierbare Ebene herunter.
Statt zu versuchen, die stochastische Antwort der KI zu tracken, clustert Sistrix über 62 Millionen echte Nutzerfragen zu Themen und aggregiert dazu (grob geschätzte) Suchvolumen.
Das Tool identifiziert darüber hinaus „ungestellte Fragen“ und die psychologischen Treiber hinter einer Suche (z. B. Unsicherheit oder Informationsbedarf für eine Kaufentscheidung).
Das ist deshalb sinnvoll, weil das Tool keine Kausalität zwischen „Optimierung“ und „Ranking“ vorgaukelt, wo es keine gibt. Es liefert stattdessen die Arbeitsgrundlage, um die Wahrscheinlichkeit zu erhöhen, als relevante Informationsquelle in die Antwort der Modelle einzufließen.
Wer die Fragen kennt, die Nutzer im Dialog stellen, kann seinen Content so strukturieren und ausbauen, dass er mit der Zeit für das RAG-System der KI zur logischsten Antwortquelle werden kann.
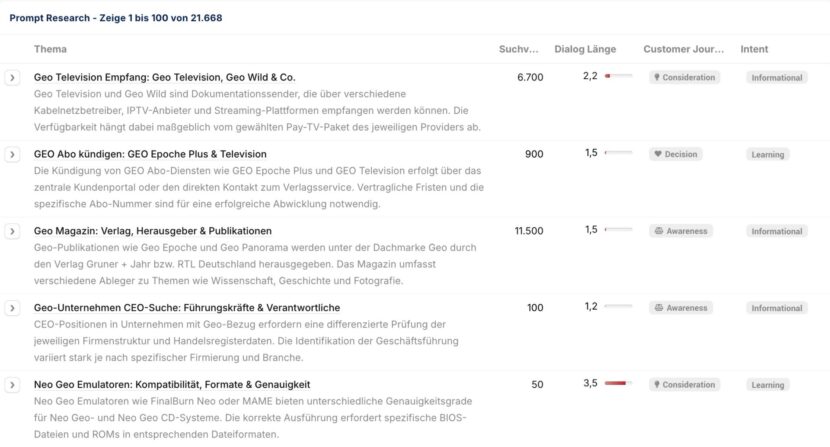
2. Der Output-Ansatz (z. B. Peec.ai)
Peec.ai verfolgt die entgegengesetzte Strategie: Es versucht, die Blackbox durch massive Simulation zu durchleuchten. Da ein einzelner Screenshot einer KI-Antwort aufgrund der Temperature (Zufallsfaktor) nicht aussagekräftig ist, beobachtet das Tool die Antworten über API-Schnittstellen in hoher Frequenz, was enorme Rechenleistung kostet und trotzdem stark lückenhaft bleiben muss, da jeder Prompt anders ist.
Das Tool schickt gezielte Prompts an verschiedene Modelle (ChatGPT, Perplexity, Gemini) und analysiert die Antworten per NLP (Natural Language Processing). Es misst den „Citation Share“, also den prozentualen Anteil, mit dem Ihre Marke oder Ihre Quellen in der synthetisierten Antwort tatsächlich vorkommen.
Hier geht es also eher um das Monitoring der „KI-Reputation“. Sie sehen schwarz auf weiß, ob die KI Ihre USPs korrekt wiedergibt oder ob sie Halluzinationen verbreitet.
Dieser Ansatz liefert zwar Snapshots der Sichtbarkeit, muss aber immer im Kontext der stochastischen Varianz gelesen werden. Es ist kein „Ranking-Tracker“, sondern zeigt Tendenzen in der KI-Wahrnehmung einer Marke auf. Nicht mehr.
Methodischer Vergleich: Input- vs. Output-Analyse
Die folgende Tabelle verdeutlicht, warum beide Ansätze unterschiedliche Probleme adressieren und welche Metriken sie jeweils heranziehen:
| Merkmal | Input-Ansatz (z. B. Sistrix) | Output-Ansatz (z. B. Peec.ai) |
| Primärer Fokus | Nachfrage-Analyse: Was fragen Nutzer? | Ergebnis-Audit: Was antwortet die KI? |
| Datenbasis | Aggregierte Millionen von Nutzer-Prompts | Stichprobenartige Echtzeit-API-Abfragen |
| Kern-Metrik | Topic-Volumen & Intent-Cluster | Citation Share & Sentiment Score |
| Technischer Vorteil | Umgeht die Stochastik der KI-Antwort | Macht reale Markennennungen sichtbar |
| Strategischer Nutzen | Planung der thematischen Relevanz | Monitoring der KI-Reputation |
| Limitierung | Kein Beweis für tatsächliches Erscheinen | Anfällig für flüchtige Modell-Varianz |
Das grundlegende Problem aller GEO Tools
So wertvoll beide Werkzeuge für die tägliche SEO-Arbeit sein können, sie können das Kernproblem nicht vollständig auflösen: Die interne Gewichtung der Modelle bleibt am Ende immer ein Rätsel. Und das wird sich auch künftig nicht ändern.
Während Google für SEO belastbare Daten in der Search Console oder im Keyword Planner bereitstellt, die von SEO-Tools verarbeitet und ergänzt werden, gibt es zu den KI-Antworten keinerlei „offizielle“ Daten.
Sistrix hilft dabei, die richtigen Themen in der Nische zu besetzen, und Peec.ai zeigt, ob und wie eine Marke in den Antworten auftaucht. Doch die Frage nach dem „Warum“, also ob die KI aufgrund des Web-Contents zitiert, auf Basis der historischen Trainingsdaten oder der Markenreputation, kann kein Tool der Welt beantworten. Entsprechend kann man nicht seriös für LLMs optimieren, sondern nur die Voraussetzungen schaffen, als Antwort in Erwägung gezogen zu werden.
Und die wichtigste Voraussetzung lautet: Wer in KI-Antworten auftauchen will, muss in seiner Branche zu den wichtigsten und verlässlichsten Quellen gehören über die man spricht und an denen man sich orientiert.
Dazu gehört, dass man weiß, was die eigene Zielgruppe sucht und wie sie sucht. Ein reines Tracking von KI-Antworten bietet dafür vergleichsweise wenig Nutzwert.
Zukunftsfähige Metriken: Erfolg messbar machen ohne Rankings
Wenn die „Position“ als Metrik ihre Bedeutung verliert, müssen Kennzahlen in den Fokus rücken, die der technischen Realität generativer Systeme gerecht werden. In der GEO-Analyse verschiebt sich der Schwerpunkt von quantitativen Listenplätzen hin zur qualitativen Präsenz innerhalb der Antwortstruktur.
Citation Share (Quellanteil)
Da LLMs ihre Antworten oft aus mehreren Quellen zusammensetzen, ist der prozentuale Anteil, mit dem eine bestimmte Domain als Referenz herangezogen wird, die entscheidende Größe. Ein „Citation Share“ von beispielsweise 30 % bedeutet nicht, dass eine Website auf „Platz 3“ rangiert. Es signalisiert vielmehr, dass diese Inhalte in jeder dritten generierten Antwort als vertrauenswürdige Stütze für die KI-Aussage fungieren. Die Arbeit geht dann aber erst los, da dieser Anteil nicht plötzlich mit ein paar Tricksereien gesteigert werden kann und sollte.
Spam wird langfristig zum Problem werden, weil dieser ebenfalls mit Hilfe von KI konsequent ausgefiltert werden wird.
Tonalität und Markendarstellung in KI-Antworten
Eine bloße Erwähnung ist im GEO-Kontext nicht gleichbedeutend mit Erfolg. Da generative Modelle Texte eigenständig formulieren, muss die Art und Weise der Nennung evaluiert werden:
- Erfolgt die Markennennung im korrekten thematischen Kontext?
- Werden Kernbotschaften (USPs) präzise wiedergegeben oder entstehen Halluzinationen? Moderne Analysen werten automatisch aus, wie Ihre Marke in KI-Antworten dargestellt wird und ob Ihre Kernbotschaften korrekt wiedergegeben werden. Dies ist eine qualitative Metrik, die für das Reputationsmanagement in KI-Umgebungen unerlässlich ist.
- Wird zwar der Content übernommen, aber die Marke bleibt eine Fußnote? In diesem Fall wurde kostenlos Content für die KI-Tools erstellt. Klicks oder sonstigen Nutzen bietet dieser Inhalt in LLMs nicht.
Sichtbarkeit in Pixeln statt Positionen
Besonders bei den AI Overviews wird eine klassische SEO-Metrik in neuer Form relevant: der vertikale Raum. Die Messung erfolgt hier nicht in Positionen von 1 bis 10, sondern im Pixel-Abstand zum Viewport-Beginn. Wenn ein AIO-Block einen signifikanten Teil des Bildschirms einnimmt, rutschen organische Ergebnisse oft vollständig aus dem unmittelbar sichtbaren Bereich. Die Sichtbarkeit wird somit als „Share of Screen“ definiert, ein Maßstab für den realen Verdrängungseffekt der KI-Antwort gegenüber klassischen Suchergebnissen.
Zwar bleiben Rankings auch künftig relevant, doch sie stehen im direkten Wettbewerb mit den KI-Antworten, die derzeit bei ca. 20 Prozent aller Suchanfragen in Google angezeigt werden.
Warum exaktes GEO-Tracking eine Illusion bleibt
Der Hype um „GEO“ als neue Marketingdisziplin hat eine Aufbruchstimmung erzeugt, die jedoch oft den Blick auf die zugrunde liegenden Realitäten verstellt. „KI-Rankings“ sind eine hilfreiche Metrik zur Orientierung, aber sie dürfen nicht als harter Beweis für Erfolg oder als direkte Folge einer spezifischen Optimierungsmaßnahme missverstanden werden.
Das größte Risiko bei der Nutzung aktueller GEO-Daten ist die Verwechslung von Korrelation und Kausalität. Da Modelle auf Milliarden von Parametern und historischen Trainingsdaten basieren, kann die Antwortpräferenz auf optimiertem Content, Markenautorität, Erwähnungen in Fachforen oder einer Änderung der internen Modell-Gewichtung beruhen.
Wer schwankende KI-Daten falsch interpretiert, läuft Gefahr, einem gefährlichen Bias zu erliegen und falsche Schlüsse zu ziehen, die sich sogar kontraproduktiv auswirken können, vor allem, wenn SEO dadurch geschwächt wird, weil Aussagen von selbst ernannten „GEO“-Experten den elementaren SEO Basics widersprechen.
Content ist nicht per se schlecht, nur weil er nicht in Sprachmodellen zitiert wird. Häufig hilft es, sich den Content einfach anzusehen und mit dem Wettbewerb zu vergleichen, statt mit dem Finger auf andere zu zeigen.
Der Versuch, jede Veränderung in der KI-Antwort allein über die Content-Qualität oder technische SEO-Faktoren erklären zu wollen, greift viel zu kurz. Das führt derzeit oft dazu, dass Budgets in die fragwürdige Manipulation von Inhalten fließen, während die eigentlichen Treiber der KI-Wahrnehmung vernachlässigt werden.
Takeaway für Betreiber von Websites
- Es gibt derzeit keine einfachen GEO-Hebel.
- Tracking ersetzt keine Markenautorität.
- Investieren Sie in SEO, Content, PR und echte Expertise.
- Produzieren Sie zitierwürdige Primärquellen statt Zusammenfassungen
- Denken Sie in Marktpräsenz, nicht in Prompt-Platzierung.
Wir können kaum beeinflussen, ob und wie zwei Menschen über uns sprechen, das gilt genauso für Chatbots, da sie nur nachplappern, was Menschen sagen. Wir können aber die Voraussetzungen schaffen, dass über uns gesprochen wird. Das wird aber nicht von heute auf morgen gelingen. Wer „GEO“ ernst nimmt, darf die Herausforderung nicht unterschätzen.
Disclaimer: Der Autor ist u.a. für Sistrix tätig, dieser Beitrag ist unabhängig davon entstanden, er stellt keine Werbung dar.
Quellen:
Sistrix: Prompt Research – Die Nachfrage hinter der KI verstehen
Google Search Central: Informationen zu AI Overviews (AIO)
Peec.ai: Monitoring von Brand Perception & Citation Share
OpenAI Research: GPT-4 Technical Report (Probabilistic Outputs)
Search Engine Land: Understanding the impact of Generative Engine Optimization (GEO)
Cornell University (arXiv): Knowledge Attribution in Large Language Models
Udo Raaf (Geschäftsführer)

Udo Raaf ist Publisher und SEO-Berater mit über 15 Jahren Erfahrung in der strategischen Suchmaschinenoptimierung für Unternehmen, Agenturen und gemeinnützige Organisationen.
Sie möchten wissen, welches Potenzial in Ihrer Website steckt?
Füllen Sie den nachfolgenden Fragebogen aus für eine unverbindliche Ersteinschätzung Ihres Projekts. Ich arbeite mit einem erstklassigen Netzwerk aus Web-Entwicklern, KI-Experten und Autoren zusammen, um maßgeschneiderte Lösungen anzubieten.
Content für Suche und KI
Wir konzipieren und produzieren hochwertigen Content für B2B-Unternehmen, der auch gefunden wird.
Fachliche Kontrolle, Keywordrecherche und Qualitätssicherung inklusive.
Jetzt Angebot anfordern