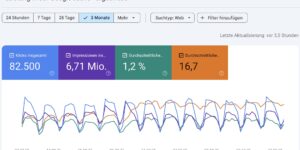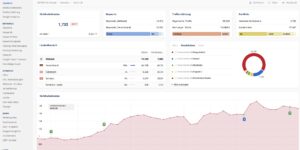
KI-Texte erkennen: Typische Formulierungen und Muster
Texte, die mithilfe von KI-Tools wie ChatGPT, Gemini oder Claude generiert wurden, lassen sich nicht sicher mit einer Software erkennen. Aber sie enthalten einige typische Formulierungen und Floskeln, die geschulten …